The future is Post-Quantum. Unfortunately, post-quantum cryptography is larger, especially the signatures. How much room is there in TLS? I had a look.
Category: Web development
CaCert.org
CaCert is a Certification Authority that works with a web of trust: people meet and assure (similar to keysigning) eachother. If you’ve been assured by enough people you’ll be able to let your ssl server key be certified by cacert. It’s a lot more secure than other CA’s who just give anyone a certificate who pays enough.
Still a hierarchical system with a CA is flawed. When the CA is compromised, the whole system fails. PGP’s web of trust hasn’t got this weakness.
(Got a nice shiny cacert certified ssl certificate on my webserver now)
Stupid PHP (1) (Strings are faster than Arrays)
When I slowly build a big string out of little bits, the worst thing to do in most languages is to just use string concatenation:
for(something) {
str .= little_bit;
}
Why? Everytime a little bit is added to str, there must be a new string allocated big enough to contain str and the new little bit. Then the actual str must be copied in. In most languages there are constructs to efficiently build strings like this instead of concatenating. StringBuffer in C#. StringIO in Python.
But no, PHP has to be stupid. There is no nice construct and you’ll end up using concatenation. So, I thought to be smart and make use of PHP array’s and implode. Arrays are here for having elements added and removed all the time so they are properly buffered and should be great at having lots of small elements added. And when I want to pack it all into one big string, I can use PHP’s builtin implode function.
I wanted to try it out and created two scripts: a.php concats a little (10byte) string one million times and b.php appends it to an array and then implodes it. And because I’m also interested in the performance of implode I got a script c.php that’s identical to b.php but doesn’t implode afterwards. These are the results:
| a.php (concat) | 0.320s |
|---|---|
| b.php (array append and implode) | 0.814s |
| c.php (array append) | 0.732s |
Indeed, string concatenation with all its allocation and copying is actually faster than plain simple array appending. PHP is stupid.
The (or at least a better) Solution to Spam
There is no easy way to distinguish between a human and a spambot. It’s an arms race which we’ll always be behind. I’m talking here about spam in more general—not only on e-mail but also on for instance Wikipedia or on blogposts. Even if we would have a perfect-solution to test whether there is a human behind something, we still have to combat cheap labour in India: real people spamming “by hand”.
I think the solution is a Web of Trust similar to that of PGP. An identity (not necessarily a person) publishes who she trusts (not to be spammy/phishy) or not trusts. Ideally everyone would be in one big web. Only someone who my blog via-via trusts may post.
Obviously one still may gather trust of people over time and enter the web of trust and then start spamming with that identity. However, then that identity will be marked untrusted by people and also the people who initially marked the identity as trusted will be less trusted. Also, there are way more sophisticated measures of establishment in the web/trust to conceive than just being trusted via-via by one identity.
There is no way to prevent spam perfectly, but the amount of work that has to go in to making an identity trusted and established in the web is several orders of magnitude greater than any other protection we have. The big problem: we don’t have such an ubiquitous web of trust yet. (Yes, it’ll be in SINP if I’ll get around to working on it)
The Future of the Internet
One of the prominent people behind the current internet discusses the history (telephony, wire oriented), the current (IP, endpoint oriented) and the future (?, data oriented) at google tech talks.
A short synopsis: the internet is having trouble at the moment for it has been designed in a time the problem was different. In these days most of the data is duplicate data, which is a tremendous waste. Also connecting to the internet (getting an address) (and resulting from that keeping everything in sync) is hard. Van suggests and predicts a data oriented internet. A bit like a secure P2P bittorrent network, but instead of on top of IP on the IP level.
It’s a very interesting talk, worth watching.
Disappearing backgrounds in IE.
In Internet Explorer in some cases backgrounds disappear seemingly randomly. The fix? Add the position: relative; style entry to the concerned div tags.
Long mySQL keys
Instead of limiting your long key (for instance a path) to approximately 800 characters (on mySQL with generic UTF8), you can hash your key and store the hash as index.
The drawback is that you need to use a quite good hash function to avoid duplicates if you want to use it for a unique or primary key. These good hash functions tend to require some computing time.
md5(microtime())
Don’t use md5(microtime()). You might think it’s more secure than md5(rand()), but it isn’t.
With a decent amount of tries and a method of syncing (like a clock on your website) one can predict the result of microtime() to the millisecond. This only leaves about a 1000 different possible return values for microtime() to be guessed. That isn’t safe.
Just stick with md5(rand()), and if you’re lucky and rand() is backed by /dev/random you won’t even need the md5(). In both cases it will be quite a lot more secure than using microtime().
SINP: Push versus Pull
SINP is pull based — I give my SINP address to someone, and he will pull the information he wants from my SINP server.
Our competitor SXIP is push based. When I use my SXIP identity I push all information I want to provide to the service — there doesn’t even have to be a SXIP server (‘homesite’).
Push has got certain advantages over pull:
- Pull is complexer: you need more traffic and more complicated traffic. Push is simpler.
- You most likely need a seperate server for pull (you need one with SINP at least), this makes you rely on your SINP server. You don’t need a real one for push.
But pull too got advantages:
- You don’t need to actively give your information. When I’m offline someone can still pull information from my SINP identity.
- Pull doesn’t require the actual information to go via your computer. If someone requests my creditcard number and I allow it, it won’t be redirected through the computer I’m using, which is safer.
SINP Certificates and redirects
Tuesday the 11th, we (Noud, Bram and I) had a meeting with some guys of the Security of Systems Group at the Radboud University. We discussed the security of the current SINP protocol. There hasn’t been a hard verdict on whether SINP is secure, because the SINP specification leaves a lot of details to implementations and SINP doesn’t make hard claims on its security yet (which can be either proved or disproved).
The meeting has yielded two new additions to SINP: document certificates1 and redirects.
First of, SINP document certificates. At the moment you can’t trust the information in a SINP document. I can forge my SINP document and claim that I’m Belgium, which I am not. To allow some trust which some people and services care about, we’ll allow certificates in your identity document. Basically you let someone sign a part of your SINP document and include that certificate.
Your goverment could sign your name in your SINP document for instance and you’d add that certificate into your document, which could be required by some services. These certificates are a bit tricky though to design, because they do need to be secure and they need to be a bit more dynamic than your usual certificate because of the way SINP documents are queried.
A second problem we encountered during the meeting was how to be able to trust your SINP server. I (and other tech savvy people) can set up their own SINP server, which we can fully trust because we set it up ourselves. Not so tech savvy people can’t — they need to rely on existing SINP servers. The problem is whether we can trust those servers with our secrets.
Cees (if I recall correctly) coined the idea that some of your secrets are already on the internet. If you’ve got a VISA creditcard number, then VISA obviously has that creditcard number, and you trust them with it. What if VISA would store the part of your SINP identity document with your creditcardnumber on its own SINP Server?
Basically I go to a big SINP provider (which I don’t trust), I create a SINP identity and put in my SINP document that you can find my creditcard number under the SINP identity bas@visa.com. This act of redirecting clients to other SINP identities is called a SINP Redirect. SINP Redirects could also proof very usefull when you change your SINP server. The only thing you’d have to do is to set up a SINP redirect in your old identity document to your new identitiy document.
Both SINP Certificates and SINP Redirects will require a lot of though to implement cleanly and simple, which is tricky.
Any thoughts would be welcome.
1: Actually, this certificates aren’t new, Bram came up with the idea quite a while ago.
sinp.rb
irb> require 'sinp'
irb> c = SINP::Client.new nil, nil, [:http]
irb> c.getPublicDocument('Kristy@w-nz.com').write
<requested version='2'>
<sinp-id>
<name><nick>kristy</nick></name>
<address type='email'>kbuiter@hotmail.com</address>
<uri>hotmail.com</uri>
</sinp-id>
</requested>
As you can see, I’ve almost finished the implementation of a Ruby SINP client — I only got to finish SINP Negotiation.
SINP
SINP is a protocol based on HTTP(S) and XML that provides you with an identity on the web. You register a so called SINP Identity on a SINP Server of your choice. To address a certain identity, we use an email like notation: bas@w-nz.com is the SINP Identity of the user bas on the SINP Server w-nz.com.
The first big feature of SINP is authentication. If someone claims to be bram@w-nz.com, I can check that by asking w-nz.com to check it. I’ll redirect that guy to w-nz.com to let him be checked by his proclaimed SINP Server. If he really is bram@w-nz.com, he’ll have a nice session cookie for w-nz.com and w-nz.com will check that. After that w-nz.com will redirect him back and I’ll ask w-nz.com whether he succeeded.
One major application of this authentication is that someone who posts a blog comment as noud@w-nz.com, really is/are the same guy(s) that posted before as noud@w-nz.com, for they are allowed by w-nz.com.
The second big feature of SINP is that each identity comes bundled with a XML document, which can store information about the owner like his name, email address, date of birth, etc. The SINP Server stores this document. The identity owner, the guy who owns the identity, can pick an access policy for each little bit of information in this document. You might want to share your real address only to those who you’ve explicitly allowed. Everyone can see the parts of your document you’ve allowed everyone access to. This is the one for bas@w-nz.com.
To get specific parts instead of the whole thing, or get to stuff you’ve limited access to, one needs to use SINP Negotiation. To get some specific information from noud@w-nz.com, I ask w-nz.com for this specific information, in the form of a few xpaths. Along with the xpaths I can send my own SINP address, bas@w-nz.com. The server will respond on each request according to the access policy which the SINP Server has set. There are several possibilities:
- Ok, the requested information will be included in the response.
- Nope, you’re denied access to that.
- Not found, that stuff isn’t in this document.
- You’ll have to ask Noud. Basically you’ll have to redirect Noud to the server, where he will be authenticated and after that he can decide whether to allow you access to it, and you can try again lateron.
- If you’re
bas@w-nz.com, you can see it. You’ll have to authenticate, though. This is done via sinp authentication as described before.
Another big feature of SINP is versioning, which allows caching. The version of a specific bit of information is send back on each response in negotiation. In a negotation request, I can specify the current version I already have. In case that specific part of the document hasn’t updated, the SINP server will let me know, instead of sending the whole thing.
One advantage of caching and negotation is that information can be kept synchronized with your document when it updates. A blog, on which you’ve posted a comment, might periodically check whether the information it retreived from your SINP document has changed. This can be done cheaply with negotiation and versioning.
SINP is easy to implement, it is quite simple. It also is portable, it uses widely supported technologies like XML and HTTP(S) as its base.
SINP is under development, but you can already (and really should) take a look to:
- The latest specification
- An almost complete SINP Server implementation in PHP. Notice that it’s a subversion repository.
- A proof of concept SINP client written in PHP. (subversion over http!)
- The w-nz.com SINP server, you can register your own SINP identity, now!
- A hacked wordpress blog to allow you to post comments with your SINP address, as a proof of concept.
- The kind people who hosted the project and who even awarded us a price for the project :-).
SINP is based on things I’ve seen floating around on the web, for instance Zef`s SPTP.
At the moment of writing we’re developing a PHP client, a Python client and continueing development of the PHP server. You’re welcome to participate!
We hope you like it, comments or any other forms of participation would be very welcome.
Bas, Bram and Noud.
SINP & Codeyard
SINP, a protocol that provides you with an identity that allows authentication and negotation of information linked with the identity as an identity document (basically the whole functionality put into a way too short sentence), which was deviced by Noud, Bram and me, has won the Capgemini Opensource Award! Lots of rejoice! You will hear more about this :-).
First SINP draft
SINP is a set of protocols to transfer a profile/identity; to authenticate owners of identities and negotiate for restricted information in protocols. It’s designed to be simple, being based on HTTPS and XML.
You can find the first draft here.
Subversion repository: https://cvs.codeyard.net/svn/webid
Acknoledgements: it’s loosely based on other stuff that has been floating around the web, like Zef’s SPTP.
Comments would be appreciated.
Update: Photo’s are in of the presentation we’ve given about SINP last wednesday:
http://www.codeyard.net/fotos/capaward-1.php
Our presentation has got several penguin mascottes.
Safe web authentication
The major problem with security of web applications is that the client sends the login name and password in plain text if https isn’t available. A nasty person with access to the network could use ARP poisening alongside packet sniffing to acquire the login, which wouldn’t really be desirable.
I stumbled accross a very interesting piece javascript which implements the md5 hash algorithm: http://pajhome.org.uk/crypt/md5/.
Using a hash makes it impossible to reverse engineer a password and makes authentication safer. An issue with this is that you only require the hash, not the password to get in. To prevent this the password should be salted before hashed.
Basicly a secure authentication via http would look like this:
Client sends request for login to server.
Server sends the login form which includes a login id and salt to the client.
Server stores the login id and salt it sent to the client.
Client sends the hash of the filled out password and received hash alongside the login id from the server to the server.
Server checks whether the hash of the password in the database and the received hash combined with the login id are valid.
Server sends whether authentication was a success.
Maybe I’ll implement an example application :-). In any case I hope that this will be employed.
Update, most authentication system used by webbased software are still vulnerable and would almost neglect the use of this by being able to hijack a session by just getting the session key. The client however could also implement javascript to use a similar method with a salt to protect the session key. The problem still is that it is extra overhead on the client and that not every client has got javascript enabled.
PHPavascript
Due to the recent hypes around Ajax and web development I’ve been thinking about a more effective method to write web applications running both on the server as on the client by writing code in just one environment and language instead of two: PHPavascript.
Having all kinds of fancy libraries to help you does help a lot; but you still got to manage transfering all data from the client and the server and back by hand; which espacially with javascript is quite tricky to do not only because it isn’t the easiest language to debug but also because every browser tends to do things a bit different with javascript.
It would be nice, I thought, to have a language for developing sererside and client side at the same time:
client TextBox mytextbox = TextBox.FromId("mytextbox");
int server function CalculateSum(first, second) {
return first + second;
}
void client function ShowSum(first, second) {
mytextbox.text = CalculateSum(first, second);
}
ShowSum(10,1000);
Basicly you mark a language entity to be either on the client or server side. The compiler would take care of the rest.
This would be really cool if it would be implemented but there would be quite a few issues:
- All client side functions and variables can be forged by the user; a naive programmer could put too much trust in functions on the client side
- Synchronizing variables on server and client side and executing functions on server and client side could with a suffisticated algorithm be managed pretty decently although it would still create a lot of overhead when the programmer doesn’t pay attention on the usage of his function/variable location. Having hundreds of variable transfers for one page would be a lot, although very possible when a programmer doesn’t take care or the compiler is too dumb.
- Language features available on the server side and only available on the client side with dirty hacks could be a bottleneck if the programmer doesnt take enough care. How to implement a mySQL connection for instance (not considering the fact that it wouldn’t be very safe in the first place)
- etc
Basicly it would be way easier to develop a web application but I don’t know what would be better: having a hard to handle situation as it is now where you are forced to think efficiently, or an easy to use environment as such a language could provide where everything works with the temptingness of not even thinking about what happens beneath the bonnet.
Although there still are these advantages:
- Vastly reduced development time
- Highly maintainable code; a compiler could even create seperate javascript files for each specific browser and compile to the desired server side language
Ajax, the hype
It’s new!
It’s cool!
And now it even got a name! Ajax.
The funny this is that it is quite old and it has been used for a long time already. It just wasn’t hyped before.
Also this phenomenon clearly illustrates the dissatisfaction with the current static Html document standard common to the world wide web. Don’t deny it: html sucks for user interfaces! Html is a format for documents notuser interfaces.
A child of Html could make a nice User Interface definition; main thing would getting rid of awquard javascript. Using a more dynamic Document Object Model, and espacially a consistant one, with some kind of Intermediate Language providing power but still security like Java, or .Net or maybe a new one, which should be hosted by the browser itself instead of a nasty plugin noone has, would be perfect.
Phalanger
Phalanger is a PHP-Compiler for the .net framework. It can be used to run existing PHP applications on asp.net webservers with far greater performance than using PHP itself:
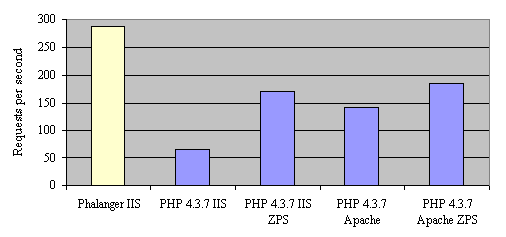
In contrary with PHP itself the bottleneck isn’t the execution of the code itself but the underlying functions for executing the code: phalanger still uses the PHP library for the PHP functions which creates a lot of overhead due to interop and makes the PHP objects not as native to .net as it could. In contrary to PHP you would be best off not using the functions but trying to use the .net ones or your own written.
In my own little benchmark for basic differences between normal .net and PHP, PHP came out to be 5000 times slower. When phalanger finaly compiles into proper .net code by avoiding any PHP library and PHP interop it would be a -lot- faster. When people would start to like it and install mod_mono on their apache webservers to run it they would probably find that they’ll be better of with asp.net with c# or vb.net. They after all got a way cleaner syntax than PHP and are happier working with the .net framework. (I don’t want to know what hacks they used at the phalanger compiler to get include and require working when compiling everything to one dll).
In the mean time microsoft is rubbing its hands
Easy Crossbrowser JavaScript
The major problem when dealing with javascript for me was that javascript acts differently on each different browser. And there are a lot of browsers supporting javascript.
Usualy to get it working it would include having for each sensitive operation a big if block. And in the a bit nicer javascripts that would become a lot. Also it becomes hard to maintain.
So what to do about it?
Actually.. C(++) gave me a possible solution. Use macro`s. It ain’t possible to use macro`s in javascript itself feasable, so what you do is you compile your javascript with macro`s to a different javascript file for each browser. Then using a simple server side script you can let the browser get what it wants.
I’m not a javascript guru, so I hardly know all the problems of each browser.
If a javascript guru does read it, please contact me – it would be great to have such a goodie.
Plugins, the web and python
Plugins for web applications seems to be discussed a lot more recently by bloggers (Zef did for instance).
Plugins usualy come in 2 shapes: hacks and modules.
The key difference between a hack and a module is that a hack changes existing behaviour and a module adds behaviour or maybe extends some. In Zef`s example he is talking about possibly adding a calander to google`s gmail – that is definitely a module.
When changing the whole interface by for instance being able to plan appointments inside other module`s (like viewing email) that would require changing those modules and basicly make it a hack.
Modules are easy to make and maintain for they form seperate entitites which don’t often conflict. Most web applications already support module-based plugins like IPB. Some more functionality can be added to modules by letting modules hook onto certain events in the other application, but this has its limits.
Where hacks are also widely used, although these are very hard to maintain and usualy conflict which eachother.
So what is the best way to write a plugin based application?
I was thinking about that when I was working on a computer version of the popular card game Magic. There are already a lot of computer version which let players play the game but the players have to apply the rules themselves.. the computer doesn’t do that for them for there are for every card a lot of exceptions and new rules are added every month. To make such a game plugins would be required.
The way I solved this is by putting everything in the game in modules/plugins. The only thing the game does is saying ‘start’ to all plugins. One plugin responds to that and that may for instance be the UI plugin which shows the main UI form and then sais ‘postgui-start’, where another plugin may respond that extends the UI form for some new features in the game and then calls ‘postseries4gui-start’. A card itself is represented by a big hashtable containing all info of that card dynamicly, including functions. Letting one create-card attack another basicly is just a big dynamicly getting properties and calling functions which all are overloaded for new rules which seems to work pretty fine.
Guess what I used to develop this highly dynamic interaction which eachother?
Python!
Python is the perfect language for plugins.
Now.. why don’t we already got really nice web applications allowing this kind of highly dynamic plugins? Web applications are although using sessions, primarily stateless.. On every page view the whole script is loaded in the memory, and executed again and then unloaded. Nothing keeps persistant. Using plugins generates a lot of overhead on espacially loading stuff for every plugin must be able to hook onto and interact with everything. Doing this with the current model webservers just don’t work.
I already made some suggestions how to solve this at the server side, but changing this would take a lot of time.
So to get back to how to get this done -now- and not later is to keep working with a modulair way exposing the most used hooks and data access.
A suggestion for gmail:
Allow SOAP based access to gmail`s features. Exactly the same amount as access as the user has got.
Then allow adding new menu items and hooks on which a call is made to your specified url, which then can work with gmail on the client-access level using SOAP calls.
Best would be for google to just expose the api of gmail and give a limited functionality dev download so people can make modules in the source and send them to google back. If they like it they’ll use it.. I guess google will come up with something like that once. Or at least I hope it.