msgpack is a fast and small binary format for json. The Python msgpack module is even a drop-in replacement for the json module.
PyPy is an implementation of Python in Python with a tracing JIT. If your Python script runs for more than 1 second, it will probably be quite faster on PyPy.
PyPy is almost a drop-in replacement for Python. Only extensions modules written in C can be a problem — for instance the msgpack module.
Thus I wrote a pure Python fallback for the msgpack module, which has been merged upstream. As a rough benchmark, I measured the pack and unpack time of a 30MB msgpack-object from the wild.
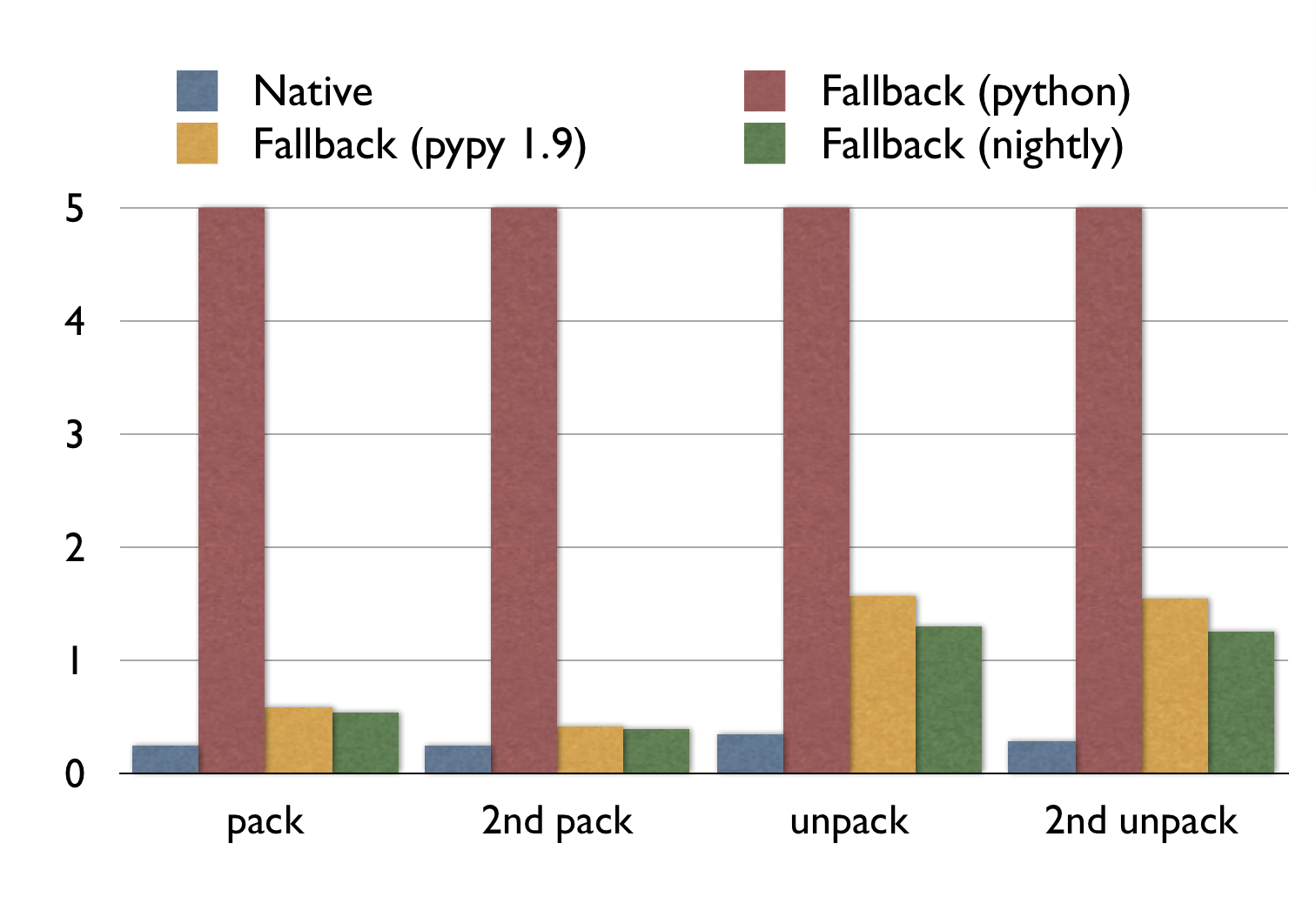
Note that:
- The execution times for the fallback with normal Python are all off the chart (15.4s, 15.1s, 10.1s, 10.0s).
- PyPy is faster on the second run: it had time to trace and optimize at runtime.
- For packing, PyPy (nightly) is almost as fast as the original C extension.
- For unpacking, PyPy (nightly) is 340% slower. Yet it more than 10 times faster than normal Python.
This code should be in the next official release of msgpack-python. If you want to use it already, check out the git repository.
The first version did not run this fast on PyPy. With PyPy’s jitviewer the compiled code and assumptions of PyPy can be examined. These are the tweaks I used in descending order of impact.
- Instead of
StringIO, the fallback uses PyPy’s ownStringBuilder.StringIOallows writing, reading, seeking and what more.StringBuilderonly allows appending and thus it is easier for PyPy to optimize. This increased performance of packing by an order of magnitude. - Using constant format strings for
struct.unpackallows PyPy to optimize it. Thusstruct.unpack("I", f.read(4)); f.read(n)instead ofstruct.unpack("I%ds"%n, f.read(4+n)) - Using
stream.write(a); stream.write(b)instead ofstream.write(a+b)increased performance. - Adding an explicit fastpath
- PyPy usually specializes a function well for its most common path, however in some cases it needs help. In this case a function returns a concatenation of several strings. However: in the most common case it only does one:
ret=''; ret+=something; return ret. PyPy does not recognize thatretis not needed at all in this case, so I added an if-statement before initializing it for the case where there is only one concatenation.
Clearly the unpacking code could be faster, if anyone with expertise on PyPy’s JIT would look at it, that would be great.
Have you tried using PyPy with cffi calling the regular msgpack c library to see if its faster than CPython using the CPython extension.
Actually, the backend of Python is written using Cython. PyPy has partial support for it. msgpack, however, does not not build successfully.
I’m talking about using the native c/c++ library (https://github.com/msgpack/msgpack-c) and connecting to it via cffi. I hear that cffi under PyPy jit adds very little overhead and is close to a native c function call.
I did not try that. I do not expect it to be faster under PyPy if it has to remain compatible to the current Python API.
If you use cffi to interface the c library you can use the Python code in both CPython and PyPy. It’s just when running under PyPy, the JIT removes most of the over head of using an ffi. Compared with ctypes, cffi is also faster on CPython. Although on CPython a module written using the CPython API will be more efficient than one that uses cffi. On PyPy, usually cffi modules will be faster than modules using the CPython API (also not all of them are compatible with PyPy).
From the plot above your native numbers also seam slow so I assume these are not the performance numbers of the of the C library I mentioned in my previous comment. Now I haven’t used msgpack myself but looking at its specs I would expect an efficiently written C code to be able to process a 30 MB message several times faster than your plots above assuming you don’t have an i/o issue (such as network or hard disk) skewing the results.
So if you are really interested in the performance you should at least give cffi a try. As it’s likely to give the best performance on PyPy and it’s compatible with CPython.
The regular msgpack library creates its own structure. This will have to be converted to Python objects. This is a big part of the work. The 30MB object becomes about 400MB of Python objects (on 64b). That is probably why the packing and unpacking performance is not what you expected.
Also: the API is not very lightweight: for instance, it allows you to specify a callback function that will be called on every batch of bytes read.
But this is just my guess. I’d love to be proven wrong.
I was going to offer a suggestion that may help reduce the memory foot print under CPython but I decided to take a peek at the code first before I suggested it.
By looking at the code there appears to be many opportunities to make it faster. So here are a few suggestions.
There are a couple of ways in which you can use the struct module. You can use the functions or the Struct class. When you use the functions it always has to parse the format strings where as if you create a struct object the format is parsed just once and you can call its methods as often as you like.
so instead of doing this inside a loop
struct.unpack(“>f”, some_string)
do something like
# outside the loop
float_struct = struct.Struct(“>f”)
# inside the loop
float_struct.unpact(some_string)
The idea is to create one struct object for each type of struct you need to deal with.
Another area to increase performance is to reduce all the string copying that is going on. The msgpack spec was designed in a way to reduce the need of copying data around. Unfortunately Python can’t take full advantage of this like you can in say C in which you can do pointer arrhythmic and a cast. Although maybe PyPy has something to help in this regard although I don’t know off the top of my head. What you can do in Python at least is keep track of the position in the message as you process it and use the pack_into and unpack_from methods provided by the struct module. These methods take a buffer and an offset which is your current position.
By making this change you will also eliminate the need to use PyPy’s StringBuilder.
Another area for improvement is to eliminate the heavy use of if and elif statements such as the ones used in the _fb_unpack method. Since the types in msgpack can be determined by reading one byte I would allocate a list of 256 tuples that would be used to aid in the unpacking process. Each tuple would contain two values. The first would be a reference to the struct object used to pack/unpack and the second for TYPE_IMMEDIATE, TYPE_RAW, TYPE_ARRAY, etc. So you would do something like this to set up the list
# define a struct for each type of msgpack type
float_struct = struct.Struct(“>f”)
float_struct = struct.Struct(“>d”)
…
# create a list to hold 256 tuples of unpack operations
unpack_operations = [None]*256
# create the tuples for the operations
unpack_operations[0x00] = …
…
unpack_operations[0xca] = (float_struct, TYPE_IMMEDIATE)
unpack_operations[0xcb] = (double_struct, TYPE_IMMEDIATE)
…
unpack_operations[0xff] = …
For types such as Positive FixNum, FixMap, FixArray, FixRaw, Negative FixNum you could set up one tuple for each one of them and use a for loop to add the reference to these tuple to the list. You can also do the same thing for the reserved types.
Then inside the _fb_unpack message you could do something like
struct_object, typ = unpack_operations[b]
struct_object.unpack_from(buffer, position)
# then do processing for the typ
That way you can eliminate all those if elif statements and increase the speed of the code as a lot less work would need to be done.
Another further improvement would be code up each of the typ operations as new private methods and instead of the 2nd item in the tuple being TYPE_IMMEDIATE, TYPE_RAW, TYPE_ARRAY, etc it would instead have a reference to these additional methods.
I suspect there are quit a few additional improvements that could be made but this should be a good starting point. I didn’t really take a good look at all the code so these suggestions were just from a quick look. Of course these suggestions also apply to the pack side.
# define a struct for each type of msgpack type
float_struct = struct.Struct(“>fâ€)
float_struct = struct.Struct(“>dâ€)
…
should have been
# define a struct for each type of msgpack type
float_struct = struct.Struct(“>fâ€)
double_struct = struct.Struct(“>dâ€)
…
Change was s/float_struct/double_struct/
PyPy (>= 2.0) optimizes pypy.unpack with constant format strings out: so initializing separate Struct objects won’t increase performance for PyPy. Have you played with jitviewer?
What was your idea for minimizing memory usage on CPython?
I was going to suggest that you include __slots__ on the classes that create or are used in the pack/unpack process. But since your only creating basic types this is not an issue. It was on purpose that I ended up not mentioning them in my previous comment as when some people learn about __slots__ they start adding them to most of the classes they create which is not a good idea. They are mainly good for class that just mainly hold small amounts of data and in situations where you need to create a large number of them. When __slots__ are used appropriately they reduce the memory overhead and increase attribute access performance under CPython. But using them comes at a cost of making your code less flexible. BTW, under PyPy the optimizations provided by __slots__ are automatic so adding them to increase performance or decrease memory size will not occur under PyPy as you get these savings for free.
It turns out performance issues you have are due to the algorithms you are using. You really need to change the architecture to see an real big performance gains. That’s why I suggested you don’t create all these sub strings from your buffer and instead keep track of your position in the message as you process the message and use the unpack_from and pack_into methods.
Not creating all the sub strings will reduce the memory overhead as well as reduce the pressure on the garbage collector while also giving you a significant boost in performance.
Now I’m not sure how much of the overhead created by all your if and elif statements PyPy are able to remove but I know implementing a more efficient algorithm that gets rid of all the if and elif will be even faster.
I haven’t seen the output of jitviewer for this code. As a matter of fact I haven’t even run the code. By looking at the code I can see that its design could be improved in a number of areas. I also see the code is written in the style of C code, which in general, Python code written like C will have poor performance issues as the run time characteristics of C and Python code are quite different. For example, function calls in C have very little overhead compare to the overhead they have in Python. So in C where calling out to lots of functions in a tight loop does not have much of an impact it does so in CPython.
When I come across code that is slow I generally do the following
* Perform a quick code review to see is there are any obvious issues
* Fix the obvious issues
* If it still too slow I run a profiler. In Python I use cProfiler and look at the top few big hitters or view the output of the profiler using a tool call runsnakerun which gives you a great way to visualize the profile data and helps you answer quickly many questions you may have while looking at the profile data.
* I then make updates to the code based on the profiller results and then repeat the profilling and code changes as necessary.
* Next for a PyPy project and only in rare cases I would look at the jitviewer if I still needed more performance.
The jitviewer should only be used in the **rare** cases where you need that little extra performance and only after you know you have already implemented good algorithms and have reviewed the profiller results.
From looking at the code I would say your nowhere near the point where you should consider using the jitviewer. Of course this is just my opinion.
Hopefully you find this useful.
Your assumption is that something like
struct.unpack("I", s[4*i:4*i+4])requires a function call and string copying. I think this is not the case in PyPy. To test this, I created a simple script and examined the generated assembly in jitviewer. here you can see that it has actually been inlined.So, for PyPy my approach seems optimal. However, for plain CPython your approach could certainly be superior to mine.
this was the test file. I used a file “test” with 1MB of bogus data. here is the log of PyPy you can plug into jitviewer.
Ah sorry there was a misunderstanding as I was not concerned about extra strings in the struct.pack and struct.unpack. The extra strings I was referring to are the ones created for example in the _fb_read method. Where the return value ret is a new substring created from copy bytes from the original buffer.
The mspack spec was designed to avoid this copying and to avoid type conversions. Although in Python you can only avoid the copying by using the unpack_from and pack_into methods. Although maybe PyPy can also avoid the type conversion but I don’t know if it is smart enough to do so at this time.
The only issue related to strings that I had with the struct.pack and struct.unpack was the parsing of the format string. I just wanted to make sure it was done only once for each msgpack type. It looks like PyPy is able to clean this up but I don’t feel like its a good idea to code with a poorer design knowing that PyPy is able to clean it up. You should be able to write good clean Python code that will execute fast on PyPy rather than writing code based on your knowledge of how PyPy is able to make improvements, as what it’s able to optimize will always be a moving target. Although in this particular case I don’t believe PyPy would make a regression in this area that would remove the optimizations that are helping you at this time.
Also before the loop is JiITed it has to run in the interrupter so the earlier operations of each msgpack type will be slower due to parsing the format string. Also what about those who may want to use this library in CPython and decide not to use cython. The performance for them is going to truly suck big time as the format string will have to be parsed every time. So that’s another reason to convert the code to use struct objects.
We have been discussing how to improve the existing code but I like to just remind you that it’s very likely that the best performance you going to see from PyPy will likely come from using cffi and the native c library. That’s basically the same approach that the cython solution is relying on.
Also, just to try to make this point a little stronger. The jitviewer should be mainly used by PyPy core developers and those building PyPy VMs. A normal developer writing Python code to run on PyPy shouldn’t have a need to use it. They can use it to point out an inefficiency that PyPy has to the core developers but it should not be used as a way to get you to write Python code in a way that has a better chance of being optimized under PyPy except for very rare occasions and even then it should only be made by those who follow closely and understand PyPy’s development.
You can personally benefit much more from learning about good design and the benefits it provides over learning how to write obscure Python code that runs fast in PyPy. In general a better design will also run faster in PyPy.
Under PyPy,
_fb_readdoes not create an extra string in the most common case.I just edited my test script to use a preinitialized
Struct. PyPy does not optimize it as well as calling juststruct.unpack. That is a shortcoming of PyPy.I agree that code should be cleanly designed without worrying about a specific implementation. Only where performance is critical, we should fiddle with toys as the jitviewer. The performance of msgpack on PyPy is critical for me, hence the effort.
I still am very doubtful that
cffiwould increase performance, for the same reasons I gave before. If you would contribute acffibackend tomsgpack-python, that would be great.I plan to use msgpack in a project I’m starting in 3-5 months. At that point in time I’ll take a look at using cffi and the msgpack library in general. Since I knew I would be using it in the near future I figured I would give you some feedback while you were working on it.
Any way good luck on the project and I will contribute a patch when I have the time to work on it.
Great! I am looking forward to it.